
Tupla en Base de Datos: Descubre cómo optimizar tu información con esta poderosa estructura
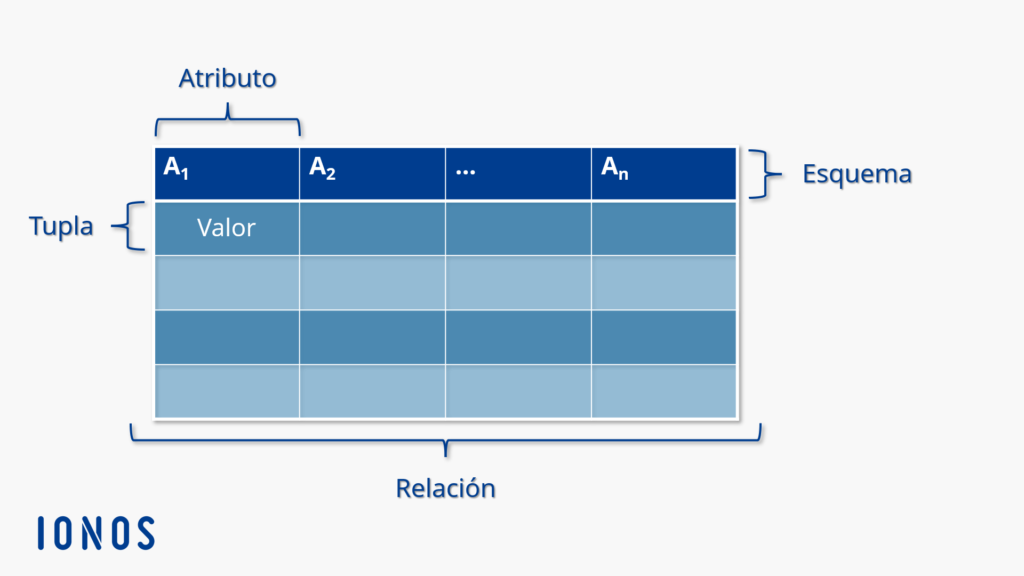
En el ámbito de las bases de datos, es fundamental contar con una estructura eficiente para almacenar y organizar la información. Una de las herramientas más utilizadas en este sentido es la tupla, que nos permite agrupar datos relacionados en un solo registro.
Exploraremos qué es una tupla en una base de datos, cómo se utiliza y cuáles son sus principales ventajas. También analizaremos casos de uso comunes y brindaremos consejos prácticos para optimizar el uso de las tuplas en tus proyectos de base de datos.
- Qué es una tupla en el contexto de una base de datos y cómo se diferencia de una fila normal
- Cómo se utiliza una tupla para optimizar la organización y búsqueda de información en una base de datos
- Cuáles son las ventajas de utilizar tuplas en comparación con otras estructuras de datos en una base de datos
- Cuáles son los principales casos de uso de las tuplas en bases de datos y en qué situaciones pueden ser especialmente útiles
- ¿Cuál es la sintaxis para crear, modificar y eliminar tuplas en una base de datos?
- ¿Cómo puedo aprovechar al máximo las tuplas en mi base de datos existente?
- ¿Existen limitaciones o consideraciones especiales al usar tuplas en una base de datos?
- ¿Cuál es la relación entre las tuplas y los índices en una base de datos y cómo puedo aprovechar esta relación para mejorar el rendimiento de mis consultas?
- ¿Cuáles son las mejores prácticas para trabajar con tuplas en una base de datos y asegurar un buen rendimiento y escalabilidad?
- Cómo puedo garantizar la integridad y la consistencia de los datos al utilizar tuplas en una base de datos
Qué es una tupla en el contexto de una base de datos y cómo se diferencia de una fila normal
Una tupla en el contexto de una base de datos es una estructura de datos que contiene un conjunto ordenado de elementos relacionados entre sí. En términos simples, una tupla se refiere a una fila individual en una tabla de base de datos.
Ahora bien, podrías pensar que una tupla y una fila son lo mismo, pero hay una diferencia clave entre ambas. Mientras que una fila normal puede contener cualquier tipo de información, una tupla tiene reglas más estrictas sobre qué tipo de datos puede contener. Una tupla está diseñada para representar un solo registro o entidad específica en una base de datos.
En otras palabras, una tupla está compuesta por un conjunto predefinido de atributos, donde cada atributo está asociado con un valor correspondiente. Estos valores pueden ser cadenas de texto, números, fechas u otros tipos de datos compatibles con la base de datos determinada.
Por ejemplo, si tenemos una base de datos de empleados, una fila normal en dicha tabla podría contener información como el nombre del empleado, su número de identificación, su puesto y su salario. Por otro lado, una tupla en esta base de datos estaría limitada a una sola entidad o registro, como los datos de un empleado específico, donde cada atributo tiene un valor específico asociado.
Uno de los beneficios de utilizar tuplas en lugar de filas normales es que las tuplas permiten un nivel adicional de especificidad y precisión en la organización y almacenamiento de la información. Además, las tuplas suelen utilizarse en combinación con otras estructuras de datos, como las relaciones o tablas, para ayudar a establecer vínculos y conexiones entre los datos almacenados en la base de datos.
Una tupla en el contexto de una base de datos es una estructura de datos que representa un solo registro o entidad específica dentro de una tabla. A diferencia de una fila normal, las tuplas tienen reglas más estrictas sobre qué tipo de datos pueden contener y están diseñadas para proporcionar un nivel adicional de precisión y especificidad en la organización y almacenamiento de la información.
Cómo se utiliza una tupla para optimizar la organización y búsqueda de información en una base de datos
Una tupla en una base de datos es una estructura de datos que permite optimizar la organización y búsqueda de información. A diferencia de otras estructuras como las listas o los arrays, las tuplas son inmutables, es decir, una vez que se crean no pueden modificarse.
Para utilizar una tupla en una base de datos, se deben seguir ciertos pasos. Primero, es necesario definir la estructura de la tupla, es decir, los campos que la componen. Estos campos pueden ser de diferentes tipos de datos, como números, cadenas de texto o incluso otras tuplas. Cada campo de la tupla tiene un nombre y un tipo asociado.
Una vez definida la estructura de la tupla, se pueden crear instancias de la misma. Cada instancia representará un registro dentro de la base de datos y contendrá los valores correspondientes a cada uno de los campos de la tupla.
Una de las ventajas de utilizar tuplas en una base de datos es que permiten asegurar la integridad de los datos. Al ser inmutables, los valores de los campos de la tupla no pueden ser modificados después de haber sido creados. Esto evita posibles errores o inconsistencias en la información almacenada.
Otra ventaja de utilizar tuplas es que facilita la búsqueda y recuperación de información. Al tener una estructura fija y predefinida, es más fácil realizar consultas y filtrar los registros según determinados criterios. Esto se debe a que cada campo de la tupla tiene un nombre asociado, lo que permite referenciarlos de manera más sencilla en las consultas.
Además, las tuplas también pueden ser utilizadas para representar relaciones entre diferentes entidades en una base de datos. Por ejemplo, se puede utilizar una tupla para representar la relación entre un cliente y un producto, donde cada campo de la tupla representa una propiedad específica, como el nombre del cliente, el nombre del producto y la cantidad comprada.
Una tupla es una poderosa estructura de datos que permite optimizar la organización y búsqueda de información en una base de datos. Al ser inmutables y tener una estructura fija, las tuplas aseguran la integridad de los datos y facilitan la realización de consultas. Además, también pueden ser utilizadas para representar relaciones entre entidades. Si quieres mejorar la eficiencia y rendimiento de tu base de datos, considera utilizar tuplas.
Cuáles son las ventajas de utilizar tuplas en comparación con otras estructuras de datos en una base de datos
En el mundo de las bases de datos, existen diferentes estructuras que nos permiten organizar y optimizar la información de manera eficiente. Una de estas estructuras es la tupla. En este artículo, exploraremos las ventajas de utilizar tuplas en comparación con otras estructuras de datos en una base de datos.
1. Simplicidad y claridad
Una de las principales ventajas de utilizar tuplas es su simplicidad y claridad. Una tupla es una colección ordenada de elementos que pueden ser de diferentes tipos. Este enfoque ayuda a mantener la información organizada y fácil de entender. Además, al utilizar tuplas, es más sencillo determinar la semántica y estructura de los datos almacenados en la base de datos.
2. Integridad de los datos
Otra ventaja importante de utilizar tuplas en una base de datos es el mantenimiento de la integridad de los datos. Cuando se utiliza una tupla, se pueden definir restricciones y reglas que deben cumplirse para garantizar que los datos sean válidos y consistentes. Esto evita la inserción de datos incorrectos o inconsistentes en la base de datos, lo cual podría ocasionar problemas en el futuro.
3. Acceso rápido a la información
Las tuplas también ofrecen la ventaja de permitir un acceso rápido a la información almacenada en la base de datos. Debido a su estructura ordenada, es más eficiente buscar y recuperar datos específicos utilizando índices o claves primarias. Esto resulta especialmente útil en bases de datos grandes con gran cantidad de registros, donde la velocidad de acceso es crítica.
4. Flexibilidad en el diseño de la base de datos
Utilizar tuplas en una base de datos ofrece flexibilidad en el diseño y estructura de la misma. Las tuplas permiten almacenar datos heterogéneos, lo que significa que es posible almacenar diferentes tipos de datos en una sola tupla. Esta característica resulta útil cuando se tienen entidades o atributos con diferentes propiedades y no se desea dividir los datos en múltiples tablas.
5. Eficiencia en el almacenamiento de datos
Otra ventaja de utilizar tuplas en una base de datos es la eficiencia en el almacenamiento de datos. Dado que las tuplas almacenan información de manera ordenada y compacta, se reducen los espacios vacíos y se maximiza la utilización del espacio de almacenamiento. Esto puede resultar en un mejor rendimiento y menor consumo de recursos de la base de datos.
Utilizar tuplas en una base de datos ofrece diversas ventajas, como simplicidad, claridad, integridad de los datos, acceso rápido a la información, flexibilidad en el diseño y eficiencia en el almacenamiento de datos. Estas características hacen de las tuplas una poderosa estructura para optimizar la información en una base de datos. Si estás buscando maximizar el rendimiento y la eficiencia de tu base de datos, considera utilizar tuplas como parte de tu estrategia de diseño y almacenamiento.
Cuáles son los principales casos de uso de las tuplas en bases de datos y en qué situaciones pueden ser especialmente útiles
Las tuplas son una estructura de datos utilizada en las bases de datos para organizar y almacenar información de manera eficiente. Son especialmente útiles cuando se necesita representar un conjunto de datos heterogéneo, es decir, cuando se tienen elementos de diferentes tipos o atributos asociados.
Uno de los principales casos de uso de las tuplas es la representación de registros en una base de datos relacional. Cada registro puede ser representado como una tupla que contiene los valores correspondientes a cada uno de sus atributos. De esta manera, se puede organizar y manipular la información de forma coherente y estructurada.
Otro caso de uso común de las tuplas es en la gestión de relaciones entre entidades. En una base de datos relacional, a menudo es necesario establecer relaciones entre diferentes tablas. Aquí es donde las tuplas entran en juego, ya que permiten representar estas relaciones de manera eficiente y optimizada.
Además, las tuplas también son ampliamente utilizadas en la optimización del rendimiento de las consultas en bases de datos. Al representar la información de manera estructurada y coherente, las tuplas permiten realizar consultas más rápidas y eficientes. Esto se debe a que se puede acceder directamente a los atributos necesarios sin tener que recorrer toda la base de datos.
Beneficios de utilizar tuplas en bases de datos
Son varios los beneficios que se obtienen al utilizar tuplas en bases de datos:
- Eficiencia: Las tuplas permiten representar la información de forma estructurada y coherente, lo que se traduce en consultas más rápidas y eficientes.
- Flexibilidad: Al ser una estructura de datos heterogénea, las tuplas permiten almacenar elementos de diferentes tipos o atributos asociados, lo que brinda mayor flexibilidad en la representación de la información.
- Optimización del rendimiento: Gracias a su estructura, las tuplas facilitan la optimización del rendimiento de las consultas en bases de datos. Esto es especialmente importante cuando se trabaja con grandes volúmenes de datos.
Las tuplas son una poderosa estructura de datos utilizada en bases de datos para organizar y almacenar información de manera eficiente. Su uso permite representar registros, gestionar relaciones entre entidades y optimizar el rendimiento de las consultas. Si estás buscando mejorar el rendimiento y la eficiencia de tu base de datos, considera utilizar las tuplas como parte de tu estrategia de optimización.
¿Cuál es la sintaxis para crear, modificar y eliminar tuplas en una base de datos?
Las tuplas son una de las estructuras fundamentales en las bases de datos relacionales. Permiten almacenar y organizar información de manera eficiente, lo que facilita la gestión de datos en una base de datos. En este artículo, aprenderemos sobre la sintaxis para crear, modificar y eliminar tuplas en una base de datos.
Sintaxis para crear una tupla
Para crear una tupla en una base de datos, se utiliza el comando INSERT INTO seguido del nombre de la tabla y los valores que se desean insertar en la tupla. La sintaxis básica es la siguiente:
INSERT INTO nombre_tabla (columna1, columna2, ..., columnaN) VALUES (valor1, valor2, ..., valorN);
Por ejemplo, supongamos que tenemos una tabla llamada "productos" con las columnas "nombre", "precio" y "cantidad_disponible". Para insertar una nueva tupla en esta tabla, podemos usar la siguiente sintaxis:
INSERT INTO productos (nombre, precio, cantidad_disponible) VALUES ('Camiseta', 29.99, 10);
En este ejemplo, estamos insertando una nueva tupla en la tabla "productos" con los valores 'Camiseta' para la columna "nombre", 29.99 para la columna "precio" y 10 para la columna "cantidad_disponible".
Sintaxis para modificar una tupla
Si deseamos modificar los valores de una tupla existente en una tabla, podemos utilizar el comando UPDATE. La sintaxis básica para actualizar los valores de una tupla es la siguiente:
UPDATE nombre_tabla SET columna1 = nuevo_valor1, columna2 = nuevo_valor2, ..., columnaN = nuevo_valorN WHERE condicion;
Por ejemplo, supongamos que queremos actualizar el precio de la camiseta en la tabla "productos" a 39.99. Podemos usar la siguiente sintaxis:
UPDATE productos SET precio = 39.99 WHERE nombre = 'Camiseta';
En este ejemplo, estamos actualizando el valor de la columna "precio" a 39.99 para todas las tuplas donde el valor de la columna "nombre" es 'Camiseta' en la tabla "productos".
Sintaxis para eliminar una tupla
Para eliminar una tupla de una tabla en una base de datos, se utiliza el comando DELETE FROM seguido del nombre de la tabla y la condición que debe cumplir la tupla para ser eliminada. La sintaxis básica es la siguiente:
DELETE FROM nombre_tabla WHERE condicion;
Por ejemplo, si deseamos eliminar la camiseta de la tabla "productos", podemos usar la siguiente sintaxis:
DELETE FROM productos WHERE nombre = 'Camiseta';
En este ejemplo, estamos eliminando la tupla donde el valor de la columna "nombre" es 'Camiseta' en la tabla "productos".
Las tuplas son fundamentales para almacenar y organizar información en una base de datos. A través de la sintaxis para crear, modificar y eliminar tuplas, podemos manipular los datos de manera eficiente y optimizar la gestión de información en nuestras bases de datos.
¿Cómo puedo aprovechar al máximo las tuplas en mi base de datos existente?
Las tuplas son una poderosa estructura de datos en el mundo de las bases de datos. Si estás buscando optimizar la manera en que gestionas la información en tu base de datos existente, las tuplas pueden ser una gran herramienta para lograrlo.
¿Qué es una tupla y por qué es relevante en las bases de datos?
Una tupla es una colección ordenada de elementos, cada uno de los cuales puede ser de cualquier tipo de dato. En el contexto de las bases de datos, las tuplas representan las filas de una tabla. Cada fila está compuesta por varios campos o atributos, y cada campo corresponde a un elemento de la tupla.
La importancia de las tuplas en las bases de datos radica en su capacidad para organizar la información de manera eficiente. Almacenar los datos en forma de tuplas permite un fácil acceso y manipulación de la información, ya que se siguen patrones consistentes y se pueden aplicar operaciones específicas a cada campo.
¿Cómo puedo utilizar las tuplas para optimizar mi base de datos existente?
Existen diversas formas en las que puedes aprovechar las tuplas para mejorar la eficiencia de tu base de datos:
Estructura clara:Al usar tuplas, puedes definir claramente la estructura de tus tablas. Esto facilita la comprensión de la base de datos tanto para los desarrolladores como para los usuarios finales.Rapidez en las consultas:Al contar con una estructura bien definida, las consultas a la base de datos pueden ejecutarse de manera más rápida y eficiente. Las tuplas permiten identificar rápidamente los campos relevantes para cada operación.Flexibilidad:Las tuplas permiten una mayor flexibilidad en la manipulación de los datos. Puedes agregar, modificar o eliminar elementos de la tupla de manera sencilla, lo que facilita la actualización de la base de datos en caso de cambios en los requerimientos.Integridad de los datos:Utilizando tuplas, es posible garantizar la integridad de los datos almacenados en la base de datos. Puedes definir restricciones y reglas que se aplicarán a cada campo de la tupla, evitando así la entrada de datos incorrectos o inconsistentes.
Utilizar tuplas en tu base de datos existente puede ser una excelente manera de optimizar la forma en que manejas la información. Desde una estructura clara hasta una mayor rapidez en las consultas, las tuplas ofrecen numerosos beneficios que te ayudarán a aprovechar al máximo tu base de datos.
¿Existen limitaciones o consideraciones especiales al usar tuplas en una base de datos?
Las tuplas en una base de datos son una poderosa estructura de datos que permite almacenar múltiples valores relacionados entre sí. Sin embargo, como cualquier herramienta, también tienen sus limitaciones y consideraciones especiales que debemos tener en cuenta al usarlas.
Límite de tamaño
Una de las principales consideraciones al utilizar tuplas en una base de datos es el límite de tamaño. Cada tupla tiene un tamaño máximo que puede ocupar en la base de datos. Si intentamos almacenar más información de la que permite el tamaño máximo de una tupla, se producirá un desbordamiento y la inserción fallará.
Es importante tener en cuenta este límite de tamaño al diseñar la estructura de nuestras tuplas y al definir los campos que las componen. Si necesitamos almacenar mucha información en una tupla, es posible que sea necesario dividirla en varias tuplas más pequeñas o utilizar otro tipo de estructuras en su lugar.
Índices y búsqueda eficiente
Otra consideración importante al usar tuplas en una base de datos es el uso de índices y cómo esto afecta a la eficiencia de las búsquedas. Los índices nos permiten acceder rápidamente a los datos que estamos buscando, pero también ocupan espacio adicional en la base de datos.
Al diseñar nuestra base de datos y utilizar tuplas, debemos tener en cuenta qué campos son más propensos a ser utilizados en búsquedas y considerar la creación de índices para optimizar la eficiencia de estas operaciones. Sin embargo, también debemos ser conscientes de que la creación de índices puede afectar el rendimiento general de la base de datos, especialmente durante las actualizaciones y eliminaciones de tuplas.
Dificultad de modificación
Una de las características de las tuplas en una base de datos es que son inmutables, es decir, una vez creadas no se pueden modificar. Si necesitamos realizar cambios en una tupla existente, debemos crear una nueva tupla con los valores actualizados y eliminar la tupla original.
Esta dificultad de modificación puede ser un inconveniente en algunos casos, especialmente cuando necesitamos realizar cambios frecuentes en la información almacenada en nuestras tuplas. En estos casos, puede ser más conveniente utilizar otro tipo de estructuras o considerar un diseño diferente para nuestra base de datos.
Consideraciones de rendimiento
Finalmente, al utilizar tuplas en una base de datos también debemos tener en cuenta las consideraciones de rendimiento. Las tuplas tienden a ocupar menos espacio en la base de datos en comparación con otros tipos de estructuras, lo que puede resultar en un mejor rendimiento en términos de uso de memoria y eficiencia en las operaciones de lectura y escritura.
Sin embargo, también debemos considerar que las operaciones de búsqueda y filtrado en tuplas pueden requerir un mayor tiempo de procesamiento en comparación con otras estructuras. Esto se debe a que las tuplas no tienen un esquema definido y las operaciones de búsqueda deben recorrer todos los campos de la tupla para encontrar la coincidencia.
Al usar tuplas en una base de datos es importante considerar las limitaciones de tamaño, la eficiencia de las búsquedas, la dificultad de modificación y las consideraciones de rendimiento. Al tener en cuenta estas consideraciones, podemos aprovechar al máximo esta poderosa estructura de datos y optimizar nuestra información en la base de datos.
¿Cuál es la relación entre las tuplas y los índices en una base de datos y cómo puedo aprovechar esta relación para mejorar el rendimiento de mis consultas?
Las tuplas son una estructura de datos fundamental en una base de datos relacional. Una tupla se puede considerar como una fila en una tabla, donde cada atributo o columna tiene un valor correspondiente. La relación entre las tuplas y los índices en una base de datos es clave para optimizar la información almacenada y mejorar el rendimiento de las consultas.
En una base de datos, los índices son estructuras que permiten acelerar la búsqueda y recuperación de datos. Un índice se crea sobre uno o varios atributos de una tabla y almacena una copia ordenada de esos valores junto con referencias a las tuplas originales. Esto permite que la base de datos pueda buscar rápidamente los datos según los criterios de búsqueda establecidos, sin necesidad de realizar una exploración completa de la tabla.
¿Cómo puedo aprovechar la relación entre las tuplas y los índices para mejorar el rendimiento de mis consultas?
A continuación, te presentaré algunas estrategias para aprovechar al máximo la relación entre las tuplas y los índices y mejorar el rendimiento de tus consultas:
Analiza tus consultas frecuentes: Antes de crear índices, es importante analizar las consultas que se realizan con mayor frecuencia en tu base de datos. Identifica los campos que se utilizan en las cláusulas WHERE o JOIN y considera crear índices en ellos. Esto ayudará a acelerar la búsqueda de datos y reducir los tiempos de respuesta.Crea índices en columnas con alta cardinalidad: La cardinalidad de una columna se refiere a la cantidad de valores distintos que puede tener. Si una columna tiene pocos valores distintos, no es necesario crear un índice en ella, ya que puede haber una rápida recuperación de datos. Sin embargo, si una columna tiene una alta cardinalidad, crear un índice en ella puede ser beneficioso, ya que reducirá el número de tuplas que deben examinarse durante una consulta.Considera crear índices compuestos: Un índice compuesto se crea sobre múltiples columnas de una tabla. Esto puede ser útil cuando las consultas involucran múltiples campos en sus cláusulas WHERE o JOIN. La creación de índices compuestos puede mejorar el rendimiento de estas consultas al permitir un acceso directo a los datos requeridos.Evita crear índices innecesarios: Aunque los índices son útiles para acelerar la búsqueda de datos, también conllevan una sobrecarga en la inserción, actualización y eliminación de tuplas. Es importante evitar crear índices innecesarios que puedan ralentizar el rendimiento general de la base de datos. Analiza cuidadosamente tus consultas y considera qué índices son realmente necesarios.Mantén tus índices actualizados: A medida que tus datos cambian, es fundamental mantener tus índices actualizados. Esto implica realizar tareas de mantenimiento, como reconstruir índices o actualizar estadísticas, para garantizar que los índices sigan siendo eficientes y reflejen correctamente la distribución de los datos.
La relación entre las tuplas y los índices en una base de datos es crucial para optimizar el rendimiento de tus consultas. Analiza tus consultas frecuentes, considera crear índices en columnas con alta cardinalidad, aprovecha los índices compuestos cuando sea necesario, evita crear índices innecesarios y mantén tus índices actualizados. Siguiendo estas estrategias, podrás aprovechar al máximo esta poderosa estructura y mejorar la eficiencia de tu base de datos.
¿Cuáles son las mejores prácticas para trabajar con tuplas en una base de datos y asegurar un buen rendimiento y escalabilidad?
Las tuplas son una estructura de datos fundamental en el mundo de la base de datos. Permiten almacenar y organizar información de una manera eficiente y compacta. Sin embargo, su correcto uso y optimización pueden marcar la diferencia en cuanto al rendimiento y escalabilidad de un sistema.
Para aprovechar al máximo las tuplas en una base de datos, es importante seguir algunas mejores prácticas:
Elegir correctamente los tipos de datos
Cuando se define una tupla en una base de datos, es esencial seleccionar los tipos de datos adecuados para cada atributo. Los tipos de datos incorrectos pueden llevar a un consumo innecesario de espacio de almacenamiento o incluso a errores durante la manipulación de los datos. Es recomendable usar tipos de datos nativos del gestor de bases de datos siempre que sea posible.
Definir índices adecuados
Los índices juegan un papel crucial en la optimización de consultas en una base de datos. Al definir tuplas, es importante considerar qué atributos se utilizarán con mayor frecuencia en búsquedas y consultas. Estos atributos deben ser candidatos para la creación de índices, lo que acelerará considerablemente la velocidad de ejecución de las consultas.
Evitar redundancias y duplicidades
Uno de los principios básicos de la base de datos es evitar la redundancia y las duplicidades en los datos almacenados. Esto implica eliminar variables o atributos que puedan obtenerse a través de la combinación de otros atributos existentes en la tupla. Además, se debe garantizar la integridad de los datos para evitar inconsistencias y conflictos durante las actualizaciones o eliminaciones.
Normalizar la estructura de la base de datos
La normalización es un proceso fundamental para optimizar una base de datos. Consiste en dividir las tuplas en múltiples tablas relacionadas, reduciendo así la redundancia y mejorando la eficiencia del sistema. Al normalizar una base de datos, se pueden aplicar diferentes niveles de normalización, como la primera forma normal (1NF), segunda forma normal (2NF) y así sucesivamente, dependiendo de los requerimientos del sistema.
Realizar consultas eficientes
Una de las ventajas principales de las tuplas es la capacidad de realizar consultas eficientes y rápidas. Para lograr esto, se deben tener en cuenta algunas técnicas importantes, como la selección de los operadores de comparación adecuados, el uso de índices creados previamente, y la optimización de las consultas mediante la utilización de cláusulas WHERE u otras construcciones SQL.
Considerar la escalabilidad del sistema
Finalmente, al trabajar con tuplas en una base de datos, se debe considerar la escalabilidad del sistema a largo plazo. Esto implica anticiparse a futuros crecimientos de datos y diseñar una estructura flexible y modular que permita incorporar nuevas tuplas sin afectar el rendimiento general del sistema. También se deben utilizar herramientas de monitoreo y administración para controlar el rendimiento de la base de datos y realizar ajustes necesarios cuando sea necesario.
Aprovechar al máximo las tuplas en una base de datos implica seguir mejores prácticas como elegir correctamente los tipos de datos, definir índices adecuados, evitar redundancias y duplicidades, normalizar la estructura de la base de datos, realizar consultas eficientes y considerar la escalabilidad del sistema. Al aplicar estas técnicas, se puede optimizar la información almacenada, mejorar el rendimiento y garantizar un sistema escalable en el tiempo.
Cómo puedo garantizar la integridad y la consistencia de los datos al utilizar tuplas en una base de datos
Las tuplas son una poderosa estructura de datos utilizada en bases de datos para garantizar la integridad y la consistencia de la información almacenada. Una tupla es similar a una fila en una tabla de base de datos, ya que contiene un conjunto fijo de atributos o campos.
Al utilizar tuplas en una base de datos, es importante comprender cómo funcionan y cómo pueden optimizar tu información. En este artículo, exploraremos cómo puedes garantizar la integridad y la consistencia de tus datos al utilizar tuplas.
¿Qué es una tupla en una base de datos?
Una tupla en una base de datos es una estructura de datos que representa una fila o registro de información. Cada tupla tiene un conjunto fijo de atributos o campos que describen los datos almacenados en ella. Estos atributos pueden ser de diferentes tipos, como cadenas de texto, números, fechas, entre otros.
Las tuplas se utilizan para organizar y estructurar la información en bases de datos relacionales. Proporcionan una forma eficiente de almacenar y recuperar datos de manera coherente y consistente.
¿Cómo puedo garantizar la integridad de los datos con tuplas?
La integridad de los datos es crucial en cualquier base de datos. Garantizar la integridad significa que los datos almacenados en la base de datos son precisos, consistentes y válidos.
Al utilizar tuplas en una base de datos, hay varias formas de garantizar la integridad de los datos:
- Definición de restricciones: puedes definir restricciones en las tuplas para asegurarte de que los datos almacenados cumplan con ciertas reglas o criterios. Estas restricciones pueden incluir verificaciones de integridad referencial, restricciones de unicidad o restricciones de valor.
- Uso de claves primarias: definir claves primarias en las tuplas puede ayudar a garantizar la unicidad de los registros y evitar la duplicación de datos.
- Aplicación de reglas de negocio: puedes utilizar tuplas para aplicar reglas de negocio específicas y asegurarte de que los datos cumplan con ciertos requisitos o condiciones.
Estas son solo algunas formas de garantizar la integridad de los datos al utilizar tuplas en una base de datos. Es importante tener un diseño adecuado de la estructura de las tuplas y considerar las necesidades específicas de tu proyecto.
¿Cómo puedo garantizar la consistencia de los datos con tuplas?
Además de la integridad, la consistencia de los datos es otra característica importante de una base de datos. La consistencia implica que los datos almacenados en la base de datos sean coherentes y estén actualizados en todo momento.
Al utilizar tuplas en una base de datos, hay varias estrategias que se pueden implementar para garantizar la consistencia de los datos:
- Transacciones: las transacciones son una forma de agrupar operaciones relacionadas en un bloque atómico. Esto significa que todas las operaciones en una transacción se ejecutan correctamente o ninguna de ellas se ejecuta. Las transacciones proporcionan un mecanismo para garantizar la consistencia de los datos al mantener la atomicidad, la consistencia, el aislamiento y la durabilidad (ACID).
- Restricciones de integridad: al definir restricciones en las tuplas, puedes garantizar que los datos ingresados cumplan con ciertas reglas o restricciones. Estas restricciones pueden ayudar a evitar inconsistencias en los datos.
- Mecanismos de sincronización: para asegurar la consistencia de los datos en un entorno multiusuario, es importante utilizar mecanismos de sincronización adecuados. Estos mecanismos evitan problemas como lecturas sucias, escrituras perdidas y actualizaciones conflictivas.
Estas estrategias pueden ayudarte a garantizar la consistencia de los datos al utilizar tuplas en una base de datos. Es importante aplicar mejores prácticas de diseño y seguir estándares establecidos para mantener la integridad y la consistencia en tus sistemas de almacenamiento de datos.
Las tuplas son una poderosa estructura de datos utilizada en bases de datos para garantizar la integridad y la consistencia de la información almacenada. Al utilizar tuplas en una base de datos, puedes garantizar la integridad de los datos mediante la definición de restricciones, el uso de claves primarias y la aplicación de reglas de negocio. Además, puedes garantizar la consistencia de los datos mediante el uso de transacciones, restricciones de integridad y mecanismos de sincronización.
Es importante comprender cómo utilizar las tuplas de manera efectiva y aplicar las mejores prácticas de diseño para garantizar la calidad y la confiabilidad de tus sistemas de almacenamiento de datos.
Una tupla es una fila en una tabla de una base de datos que contiene información relacionada o registros.
Las tuplas se utilizan para organizar y almacenar datos de manera estructurada, facilitando su consulta y manipulación.
Una tupla puede tener cualquier cantidad de valores, dependiendo de la estructura de la tabla a la que pertenece.
Los valores de una tupla se acceden mediante la especificación del nombre de la columna o el índice correspondiente.
En general, una vez que una tupla ha sido creada, sus valores no suelen modificarse. Sin embargo, es posible actualizar los valores de una tupla mediante sentencias SQL específicas.
Entradas relacionadas